前言
曾在和吉利研究院的预研项目以及联电预研项目中,接触过TDA4的开发。翻看一下当时的note,重新总结一下。
总体参考资料
参考文档
BSP 8.00 https://software-dl.ti.com/jacinto7/esd/processor-sdk-rtos-jacinto7/08_00_00_12/exports/docs/pdk_jacinto_08_00_00_37/docs/userguide/jacinto/getting_started.html BSP 8.01 https://software-dl.ti.com/jacinto7/esd/processor-sdk-linux-jacinto7/08_01_00_07/exports/docs/linux/Foundational_Components_Multimedia_D5520_VXE384.html#v4l2-video-encoder-test-app
BSP 8.02 2.1. Release Notes — Processor SDK Linux for J721e Documentation https://software-dl.ti.com/jacinto7/esd/processor-sdk-linux-jacinto7/08_02_00_03/exports/docs/devices/J7/linux/Release_Specific_Release_Notes.html
Deep learning
TIOVX 用户指南:概述 https://software-dl.ti.com/jacinto7/esd/processor-sdk-rtos-jacinto7/08_00_00_12/exports/docs/tiovx/docs/user_guide/index.html
TI 深度学习产品用户指南:TIDL - TI 深度学习产品 https://software-dl.ti.com/jacinto7/esd/processor-sdk-rtos-jacinto7/08_01_00_13/exports/docs/tidl_j7_08_01_00_05/ti_dl/docs/user_guide_html/index.html
CCS Debug
OPENVX
https://zhuanlan.zhihu.com/p/469951086 专有名词 相关培训资料 https://edu.21ic.com/lesson/2372
(他人总结)TDA4VM基本知识:SDK, TIDL, OpenVX
TDA4的基本知识,包括数据手册研读,SDK介绍,TIDL概念。 TDA4VM官网, TI e2e论坛 TDA4系列文章:
- TDA4①:SDK, TIDL, OpenVX
- TDA4②:环境搭建、模型转换、Demo及Tools
- TDA4③:YOLOX的模型转换与SK板端运行
- TDA4④:部署自定义模型 TDA4VM芯片数据手册研读 TDA4VM数据手册 适用于 ADAS 和自动驾驶汽车的TDA4VM Jacinto™ 处理器,具有深度学习、视觉功能和多媒体加速器的双核 Arm® Cortex®-A72 SoC 和 C7x DSP. Jacinto 7系列架构芯片含两款汽车级芯片:TDA4VM 处理器和 DRA829V 处理器,前者应用于 ADAS,后者应用于网关系统,以及加速数据密集型任务的专用加速器,如计算机视觉和深度学习。二者都基于J721E平台开发。 多核异构
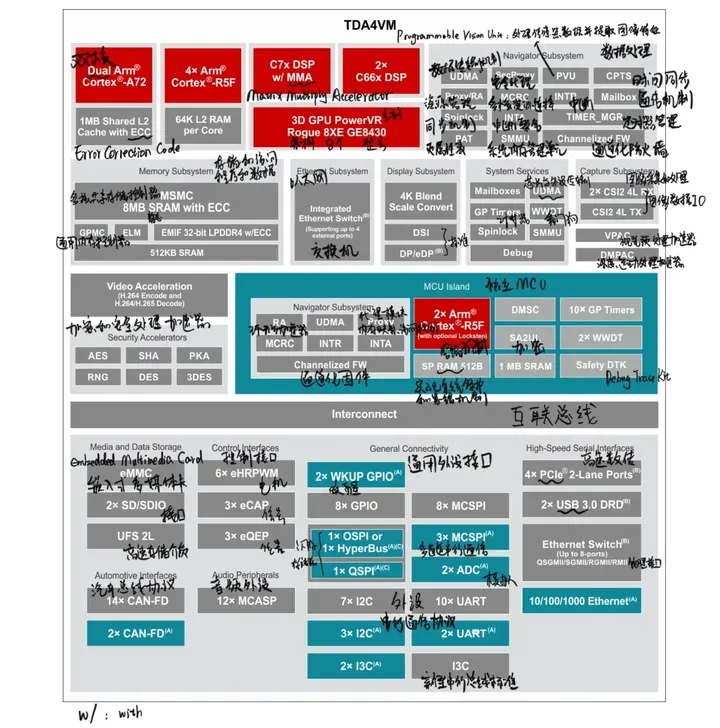
处理器内核
- C7x 浮点矢量 DSP,性能高达 1.0GHz、 80GFLOPS、256GOPS:C7x是TI的一款高性能数字信号处理器,其中的浮点矢量 DSP 可以进行高效的信号处理、滤波和计算,大幅提高神经网络模型的计算效率。 GHz-每秒钟执行10亿次计算,GFLOPS-每秒10亿次浮点运算,GOPS-每秒10亿次通用操作。
- 深度学习矩阵乘法加速器 (MMA),性能高达8TOPS (8b)(频率为1.0GHz):可以高效地执行矩阵乘法和卷积等运算。 TOPS-每秒万亿次操作,8b-8位精度的运算。
- 具有图像信号处理器(ISP)和多个视觉辅助加速器的视觉处理加速器(VPAC):可以高效地执行图像处理、计算机视觉和感知任务。
- 深度和运动处理加速器(DMPAC):可以高效地执行深度计算和运动估计等任务。
- 双核 64 位 Arm® Cortex®-A72 微处理器子系统,性能高达 2.0GHz:可以高效地执行复杂的应用程序。
- 每个双核 Cortex®-A72 集群具有 1MB L2 共享缓存
- 每个 Cortex®-A72 内核具有 32KB L1 数据缓存 和 48KB L1 指令缓存 L1缓存(一级缓存):小而快,缓存CPU频繁使用的数据和指令,以提高内存访问速度;L2:大,帮助CPU更快地访问主内存中的数据。
- 六个 Arm® Cortex®-R5F MCU,性能高达 1.0GHz:一组小型、低功耗的微控制器单元,用于处理实时任务和控制应用程序
- 16K 指令缓存,16K 数据缓存,64K L2 TCM(Tightly-Coupled Memory)
- 隔离 MCU 子系统中有两个 Arm® Cortex®-R5F MCU
- 通用计算分区中有四个 Arm® Cortex®-R5F MCU
- 两个 C66x 浮点 DSP,性能高达 1.35GHz、 40GFLOPS、160GOPS:另一款高性能数字信号处理器,可以高效地执行信号处理、滤波和计算任务。
- 3D GPU PowerVR® Rogue 8XE GE8430,性能高达 750MHz、96GFLOPS、6Gpix/s:专门用于图形处理的硬件单元,可以实现高效的图形渲染和计算。 Gpix/s-每秒可以处理10亿像素数
- 定制设计的互联结构,支持接近于最高的处理能力:处理器内部的互连结构,用于连接各种硬件单元,并支持高效的数据传输和协议。 SDK
Download:PROCESSOR-SDK-J721E,提供两套SDK(软件架构不同):
- PSDK RTOS and Linux,用于J721E-EVM
- PSDK Linux for Edge AI,用于TDA4VM-SK RTOS and Linux SDK work together as a multi-processor software development kit,用于ADAS领域,更多的外设和驱动放在RTOS端,便于实时处理 ,自定义性更强,开发难度更大 Edge AI SDK主要基于Linux开发,用于工业领域,工作量少但实时性差,无法发挥芯片全部性能 ^0 Processor SDK RTOS (PSDK RTOS) PSDK RTOS Block Diagram
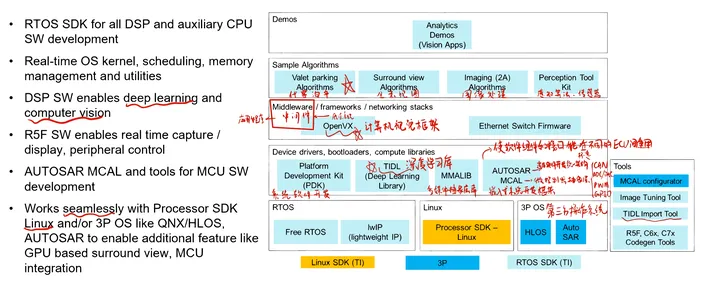
Hardware
- Evaluation Module (EVM):Ti 推出的硬件开发板。用于快速原型设计和新产品开发,可以帮助开发人员在短时间内实现复杂的嵌入式系统功能, EVM Setup for J721E
- JTAG:debug execution, load program via JTAG-No Boot Mode
- uart:prints status of the application via the uart terminal. Software Recommend IDE:Code Composer Studio (CCS), CCS Setup for J721E Demos Prebuilt Demos:直装 Build Demos from Source: Linux, Windows(很少) SDK Components The following table lists part of the top-level folders in the SDK package and the component it represents.
| Folder | Component | User guide |
|---|---|---|
| vision_apps | Vision Apps | Demos |
| pdk_jacinto_* | Platform Development Kit | PDK |
| mcusw | MCU Software | MCU SW |
| tidl_j7_* | TI Deep learning Product | TIDL Product |
| tiovx | TI OpenVX | TIOVX |
| tiadalg | TI Autonomous Driving Algorithms | TIADALG |
RTOS SDK 中集成了众多的Demo展示TIDL在TDA4处理器上对实时的语义分割和 SSD 目标检测的能力。如下图, Vision Apps User Guide 中 AVP Demo 的展示了使用TIDL对泊车点、车辆的检测。 [^1] [^1]:Deep Learning with Jacinto™ 7 SoCs: TDA4x | 当深度学习遇上TDA4
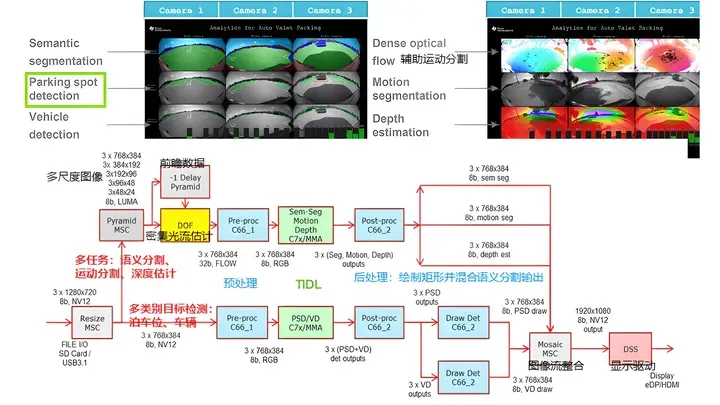
Processor SDK Linux SDK Components
| Folder | Component |
|---|---|
| bin | 包含用于配置主机系统的帮助程序脚本和目标设备。这些脚本中的大多数都由setup.sh使用脚本。 |
| board-support | 主要包含linux内核源码,uboot源码,及其他组件。 |
| configs | yocto工具的构建链接(yocto构建大约需要十几个小时,一般情况下不会去编译yocto。)。 |
| docs | 直接打开index.html,即可阅读整个SDK的官方文档。 |
| example-applications | 包含一些benchmarks等app demo。 |
| filesystem | 存放默认、最小的文件系统。 |
| linux-devkit | 交叉编译工具链和库以加快目标设备的开发速度。 |
| Makefile | 顶级编译脚本(make)。 |
| patches | 补丁、预留目录。 |
| Rules.make | 设置顶级生成文件使用的默认值以及子组件生成文件。 |
| setup .sh | 配置用户主机系统和目标开发系统。 |
| yocto-build | 此目录允许重建SDK组件和使用Yocto Bitbake的文件系统。 |
Linux SDK最主要是用于A72核心上的启动引导、操作系统、文件系统,一般只有在修改到这部分的时候才会使用到Linux SDK。 PSDK Linux for Edge AI 对于Edge AI,无需对深度学习算法进行深入了解,使用python或C++即可进行部署,不支持的算法可以放在ARM端计算和实施推理,TI会自动生成推理文件,如下图;
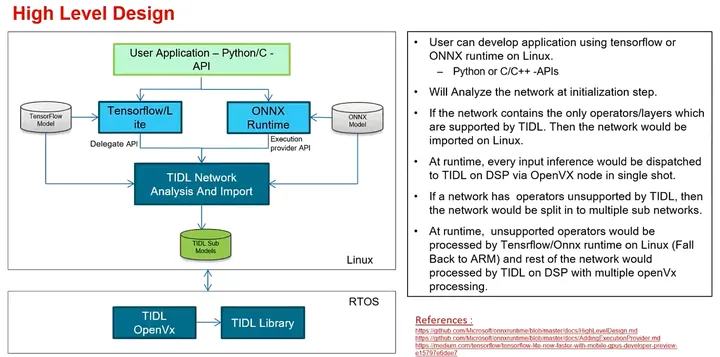
而对于ADAS领域,要把深度学习算法都放在TIDL端,最大化利用算力,需要手写加速算子进行自定义层的设计; 两套SDK部署深度学习算法的区别如下:

TDA4VM-SK开发板
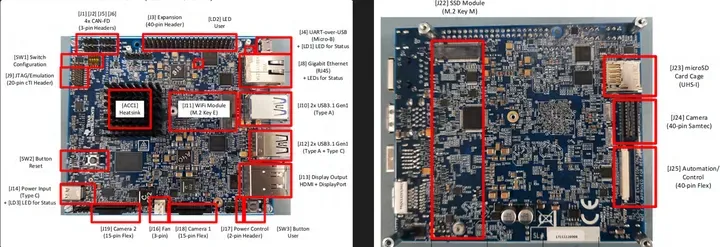
TDA4VM processor starter kit for edge AI vision systems
图 TDA4VM-SK SK-TDA4VM Evaluation board | TI.com SK-TDA4VM 用户指南, 提供了 SK-TDA4VM 的功能和接口详细信息 Processor SDK Linux for Edge AI Documentation Processor SDK Linux for SK-TDA4VM Documentation TI 的 TDA4VM SoC 包含双核 A72、高性能视觉加速器、视频编解码器加速器、最新的 C71x 和 C66x DSP、 用于捕获和显示的高带宽实时 IP、GPU、专用安全岛和安全加速器。 SoC 经过功率优化,可为机器人、工业 和汽车应用中的感知、传感器融合、定位和路径规划任务提供一流的性能。 TDA4VM Edge AI Starter Kit (SK) 是一款低成本、小尺寸板,功耗大约20W,能提供8TOPS深度学习算力,支持Tensorflow Lite,ONNX,TVM,GStreamer接口 Features
- 性能 - TDA4VM处理器提供8 TOPS的深度学习性能,并以低功耗实现硬件加速的边缘人工智能。
- 摄像头接口 - 两个与树莓派兼容的CSI-2端口,以及一个高速40针Semtec相机连接器,可连接最多八个相机(需要TIDA-01413传感器融合附加卡)。
- 连接性 - 三个USB 3.0 Type A端口,一个USB 3.0 Type C端口,一个以太网口,一个M.2 Key E连接器和一个M.2 Key M连接器,四个CAN-FD接口,通过一个USB桥接器支持四个UART终端。
- 内存 - DRAM,LPDDR4-4266,总计4GB内存,支持行内ECC(Error Checking and Correcting”)。
- 显示 - DisplayPort支持最高4K分辨率和MST功能,以及1080p HDMI。 TIDL TIDL(TI Deep Learning Library)是TI平台基于深度学习算法的软件生态系统,其特性和支持[^2]可以将一些常见的深度学习算法模型快速的部署到TI嵌入式平台。 [^2]:Embedded low-power deep learning with TIDL
Features: Interoperability, High Compute, High Memory Bandwidth, Scalability Popular operators supported: Convolution, Pooling, Element Wise, Inner-Product, Soft-Max, Bias Add, Concatenate, Scale, Batch Normalization, Re-size, Arg-max, Slice, Crop, Flatten, Shuffle Channel, Detection output, Deconvolution/Transpose convolution Functions: Import trained network models into .bin files that can be used by TIDL. The following model formats are currently supported:
- Caffe 模型(使用 .caffemodel 和 .prototxt 文件) - 0.17 (caffe-jacinto in gitHub)
- Tensorflow 模型(使用 .pb 或 .tflite 文件) - 1.12(TFLite - Tensorflow 2.0-Alpha)
- ONNX 模型(使用 .onnx 文件 和 .prototxt 文件) - 1.3.0 (官方onnx已经到了1.14) Run performance simulation tool on PC to estimate the expected performace of the network while executing the network for inference on TI Jacinto7 SoC Execute the network on PC using the imported files and validate the results.bin Execute the network on TI Jacinto7 SoC using the imported files and validate the results.bin
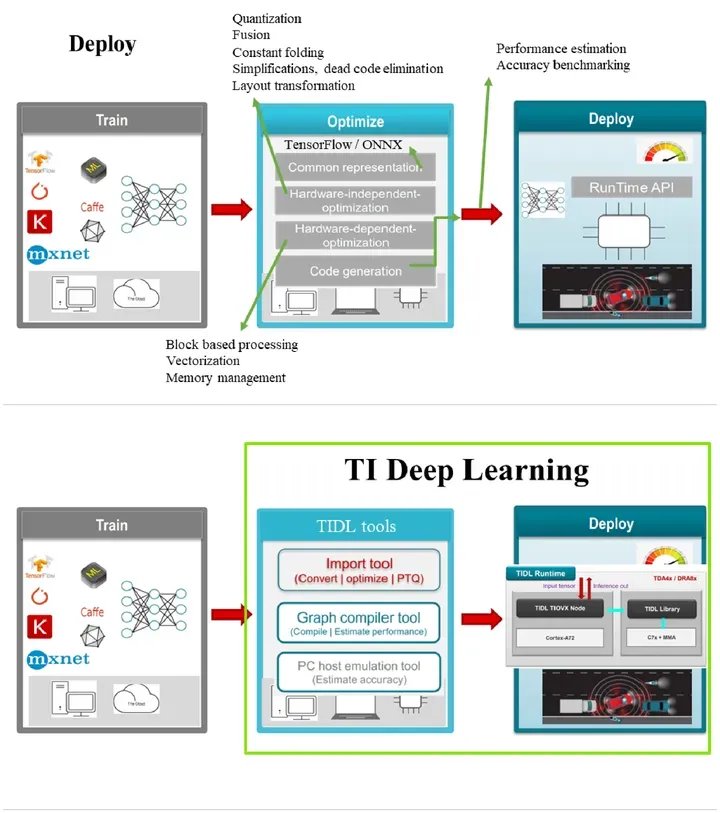
TIDL当前支持的训练框架有Tensorflow、Pytorch、Caffe等,用户可以根据需要选择合适的训练框架进行模型训练。TIDL可以将PC端训练好的模型导入编译生成TIDL可以识别的模型格式,同时在导入编译过程中进行层级合并以及量化等操作,方便导入编译后的模型高效的运行在具有高性能定点数据感知能力TDA4硬件加速器上。 TIDL Importer RTOS SDK 中的 ti_dl 提供了 TIDL Importer 模型导入工具,模型可视化工具等,非常便捷地可以对训练好的模型进行导入。
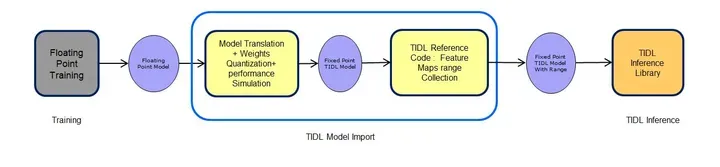
RTOSsdk/tidl_j721e/ti_dl/utils/tidlModelImport
-
- 读取导入配置文件;
-
- 转换并导入网络层和算子(operators)到TIDL net file,计算层大小和缓冲区大小,并尽可能合并层;
-
- 生成量化配置文件,调用量化工具(quant tool)进行范围采集,并更新TIDL net file;
-
- 生成用于网络编译器(network compiler)的配置文件,并调用编译器进行性能优化;
-
- [Optional] 调用GraphVisualiser来生成网络图;
-
- 导入工具将在最后结束检查模型;
-
- 最后,如果没有错误,可以用于部署。 总的来说,导入工具将在内部运行quantization, network compilation, performance simulation internally, 并生成文件: Compiled network and I/O files used for inference Performance simulation results for network analysis in .csv
TIDL Quantization 量化方法
Tidl tools quantization,torchvision-Quantization 把浮点计算(Float)转换成定点(Int)计算,是一种基于计算机存储和计算过程特点,提升(端侧)模型推理速度,并维持稳定精度的模型压缩方法。
- 浮点计算在成本和功耗效率方面不高。这些浮点计算可以用定点计算(8 or 16 bit)来代替,同时不会丢失推理精度。
- J7平台的矩阵乘法加速器(MMA)支持深度学习模型的8位、16位和32位推理。
- 当进行64x64矩阵乘法时,8位推理支持4096 MACs(Multiply–Accumulate Operations) per cycle的乘法器吞吐量。因此,8位推理适用于J7平台。 (16位和32位推理会显著消耗性能。 16位推理的乘法器吞吐量为每个周期1024个MAC。 所需的内存I/O会很高。) TIDL中需要量化的层:Convolution Layer、De-convolution Layer、Inner-Product Layer、Batch Normalization (Scale/Mul, Bias/Add, PReLU)
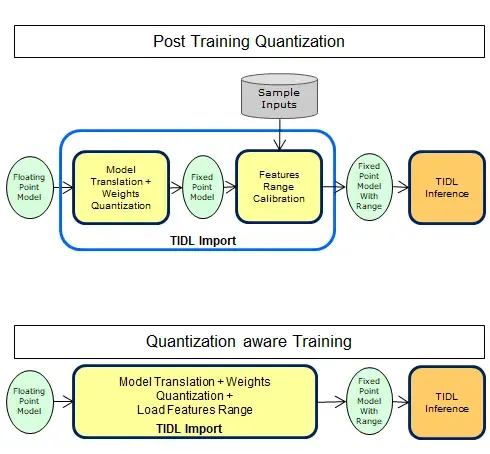
- Quantization options:
- Post Training Quantization (PTQ, 训练后量化、离线量化)
- Training for Quantization (QAT,训练时量化,伪量化,在线量化)
- Quantization aware Training
从零开始玩转TDA4之模型量化 TI’s Edge AI TIDL is a fundamental software component of TI’s Edge AI solution. 在TIDL上,深度学习网络应用开发主要分为三个大的步骤:
-
- 基于Tensorflow、Pytorch、Caffe 等训练框架,训练模型
-
- 基于TDA4VM处理器导入模型: 训练好的模型,需要使用TIDL Importer工具导入成可在TIDL上运行的模型。导入的主要目的是对输入的模型进行量化、优化并保存为TIDL能够识别的网络模型和网络参数文件
-
- 基于TI Jacinto7TM SDK 验证模型,并在应用里面部署模型^3
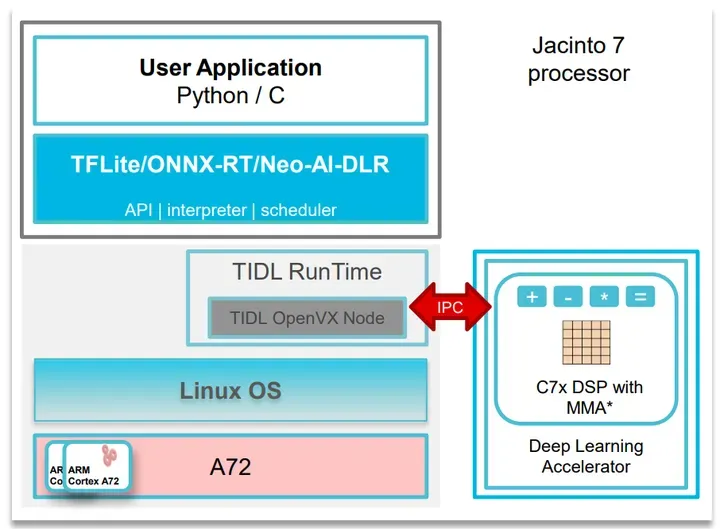
TIDL Runtime(TIDL-RT)是运行在TDA4端的实时推理单元,同时提供了TIDL的运行环境,对于input tensor,TIDL TIOVX Node 调用TIDL 的深度学习加速库进行感知,并将结果进行输出。
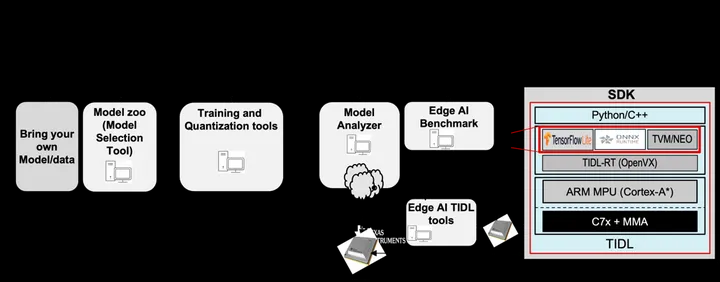
TI’s EdgeAI Tools:Training and quantization tools,make DNNs more suitable for TI devices.
- Model ZOO:A large collection of pre-trained models for data scientists,其中有YOLO例程
- Edge AI TIDL Tools:used for model compilation on X86. Artifacts from compilation process can used for Model inference, which can happen on X86 machine or on development board with TI SOC.
- Edge AI Benchmark:provides higher level scripts for model compilation,and perform accuracy and performance benchmark.
- Edge AI Studio:Integrated development environment for development of AI applications for edge processors.(需授权)
- EdgeAI-ModelMaker: Command line Integrated environment for training & compilation,集成了edgeai-modelzoo, edgeai-torchvision, edgeai-mmdetection, edgeai-benchmark, edgeai-modelmaker OpenVX OpenVX 视觉加速中间件是芯片内部的硬件加速器与视觉应用间的桥梁(中间件:用于简化编程人员开发复杂度、抽象软硬件平台差异的软件抽象层),是个由Khronos定义的API框架,包括:宏的定义与含义,结构体的定义与含义,函数的定义与行为。 基本概念
- Vx_context:一个context就是一个运行环境,包含多种不同的功能,在不同场景下被调度。一般很少有使用到多context的场景;
- Vx_graph:一个graph就是一个功能,是由多个步骤连接在一起的完整功能;
- Vx_node:一个node就是一个最小的调度单元,可以是图像预处理算法,可以是边缘检测算法。 每个进程内可以有多个context(上下文),每个context内可以有多个graph(图,或连接关系),每个graph内可以有多个node(节点)。 [^4] [^4]:TIOVX – TI’s OpenVX Implementation
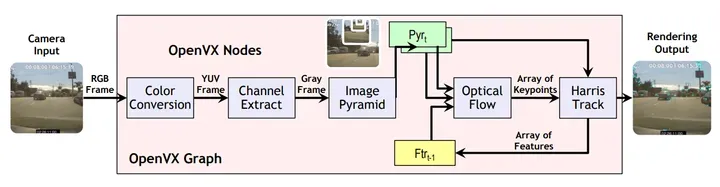

//Example Program vx_context context = vxCreateContext(); //创建 OpenVX 上下文,即整个应用程序的运行环境 vx_graph graph = vxCreateGraph( context ); //在上下文中创建一个图,表示图像处理的流程 vx_image input = vxCreateImage( context, 640, 480, VX_DF_IMAGE_U8 ); vx_image output = vxCreateImage( context, 640, 480, VX_DF_IMAGE_U8 ); //创建输入和输出图像,分别用于存储输入和处理后的图像。 vx_image intermediate = vxCreateVirtualImage( graph, 640, 480, VX_DF_IMAGE_U8 ); //创建虚拟图像,用于存储第一次处理后的结果,供下一步处理使用 vx_node F1 = vxF1Node( graph, input, intermediate ); vx_node F2 = vxF2Node( graph, intermediate, output ); //创建两个节点,分别表示两个不同的图像处理操作,并将它们添加到图中 vxVerifyGraph( graph ); //验证图的正确性 vxProcessGraph( graph ); //执行图像处理

基本数据结构
Vx_image, Vx_tensor, Vx_matrix, Vx_array, Vx_user_object_data
OpenVX规范了标准化的数据结构,基本满足了嵌入式系统的主要需求,尤其是这种数据结构的描述方法对嵌入式系统非常友好:支持虚拟地址、物理地址等异构内存;提供了数据在多种地址之间映射的接口;提供了统一化的自定义结构体的描述方法。
TIOVX
TIOVX 是TI公司对OpenVX的实现。
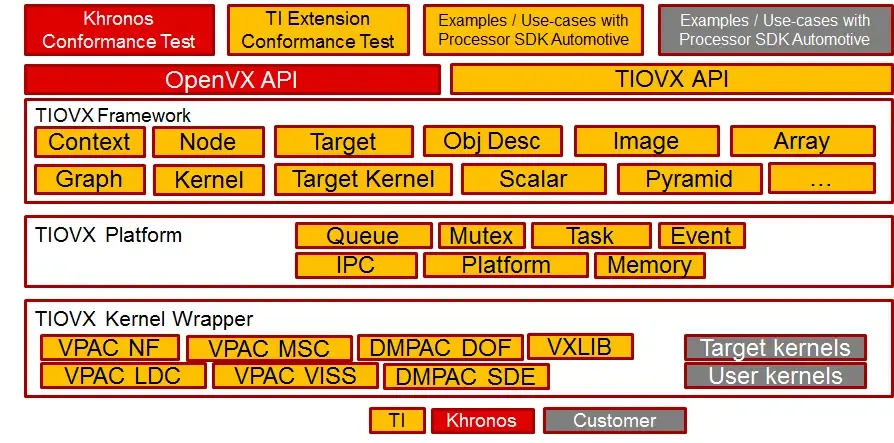
TIOVX Platform提供了特定硬件(如TDAx, AM65x)的操作系统(如TI-RTOS, Linux)调用API。TIOVX Framework包含了官方OpenVX的标准API和TI扩展的API,其中包括
public: Context, Parameter, Kernel, Node, Graph Array, Image, Scalar, Pyramid, ObjectArray ; TI: Target, Target Kernel, Obj Desc。 优势
- TI官方提供OpenVX的支持,提供标准算法的硬件加速实现,提供各个功能的Demo,能够简化开发调试工作。
- 简化多核异构的开发,可以在X86模拟运行,所有的板级开发和调试都位于A72 Linux端,减少了对RTOS调试的工作量。
- OpenVX提供了数据流调度机制,能够支持流水线运行,简化了多线程和并行调度的工作。结合RTOS的实时特性,减少Linux非实时操作系统带来的负面影响^5
PyTIOVX: Automated OpenVX “C” Code Generation
启动流程
实际操作说明
uboot 设置mac 地址,分配ip
mac 地址 24:76:25:a4:12:01 192.168.11.97 setenv ethaddr 24:76:25:a4:12:01 saveenv
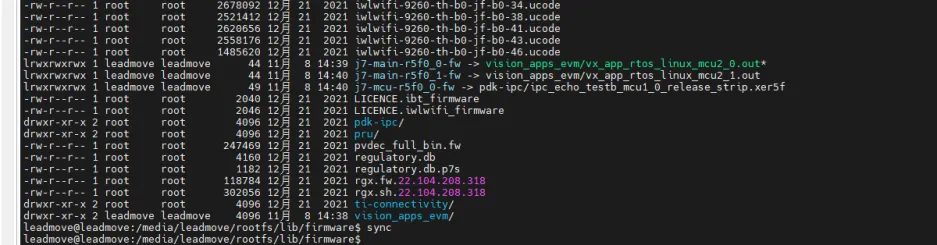
- BOOT 目录完全替换
- rootfs/boot 更换设备树
- 增加vision_apps_evm 删除原有firware 软连接,并替换相关mcu_2_0
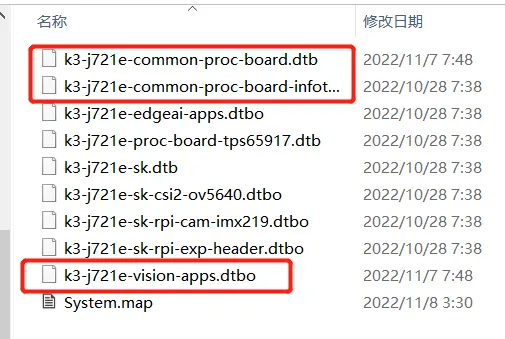
uboot启动命令
1
setenv mmcdev 1 setenv bootpart 1:2 setenv args_mmc 'run finduuid;setenv bootargs console=${console} ${optargs} root=PARTUUID=${uuid} rw rootfstype=${mmcrootfstype}' saveenv
- 重设环境 env default -a
说明
Ti 针对TDA4这款芯片,提供两个BSP,一个是RTOS的BSP,一个是Linux的BSP。两款BSP都使用过。在具体开发中,Linux BSP 基本不会有啥大的变动(内核/ROOTFS有预编译版本),而RTOS则是开发应用主力,应用只有在经过TI init初始化之后,才能加载多核资源。Ti 也有裸核运行的方式用来快速验证驱动。
R5 启动流程图
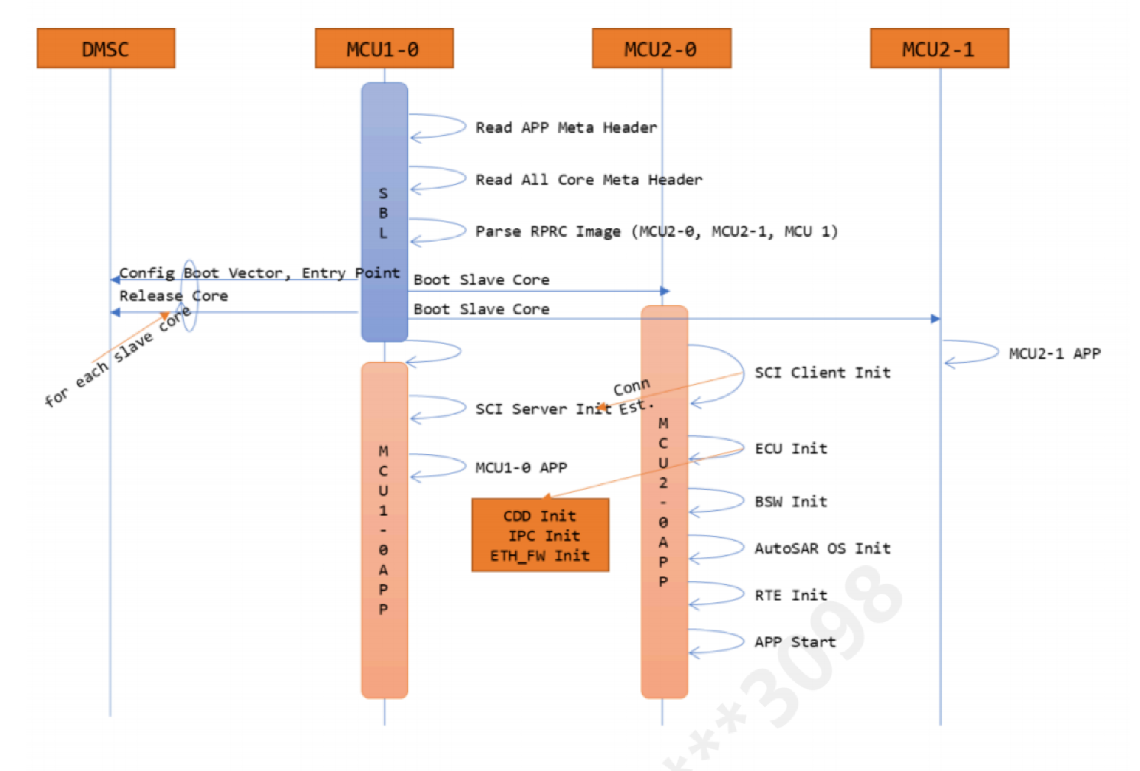
上图说明了R5的启动流程,因为TDA4这款芯片是多核架构,所以,有时候可以在RTOS 的进行一些性能优化,如将一些启动放在了R5里面。这样可以加速Linux 启动的效率。


