前言
前阵子报名参加了百度深度学习入门七天cv课程,说说我的一些心得与体会吧。
课程目录见下:
图像处理原理与深度学习入门
主流的深度学习框架有很多拉,百度的飞浆,pytorch(偏学术),tf2,caffe,dgl等等。
上张老图如下:

百度的飞浆
有一说一,白嫖还是爽啊,GPU玩的飞起。可以参考官方文档,进行快速入门。在强烈推荐某个老哥的csdn博客,仔细研读,满满的收获!!!
实战可视化
数据准备
模拟浏览器 –> 往目标站点发送请求 –> 接收响应数据 –> 提取有用的数据 –> 保存到本地/数据库
!!!!官方给的baseline里面爬虫程序写的好精致啊!!!代码封装与注解都很到位
可视化
用的是百度开源的echarts,非常好用的数据可视化工具,强烈推荐!!!就是国内访问速度不理想~~~
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//主要修改代码
设置初始宽度,高度
m = Pie(init_opts=opts.InitOpts(width="1600px", height="1000px"))
传参
m.add("累计确诊", [list(z) for z in zip(labels, counts)], center=["35%", "50%"])
//系列配置项,将{b}(数据项名称),{c}(数值)关联起来起来,并设置颜色默认填充
m.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"),position="center",is_show=True)
//全局配置项,配置标题
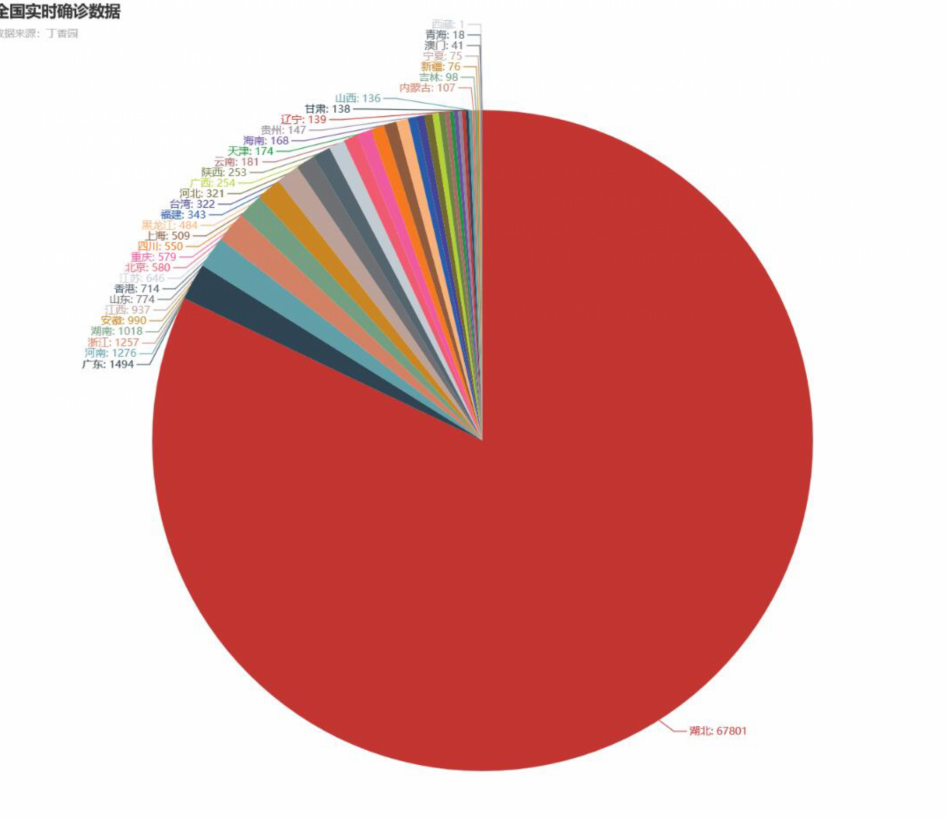
m.set_global_opts(title_opts=opts.TitleOpts(title='全国实时确诊数据',
subtitle='数据来源:丁香园'),
legend_opts=opts.LegendOpts(is_show=False))
//render()会生成本地 HTML 文件,默认会在当前目录生成 render.html 文件,也可以传入路径参数,如 m.render("mycharts.html")
m.render(path='/home/aistudio/data/全国实时确诊数据.html')
效果图片
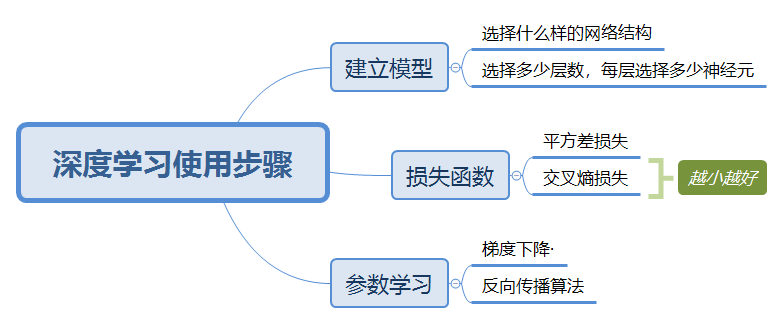
深度学习原理与使用方法
使用步骤如下:
实战手势识别
所定义的dnn模型,效果不是很理想,参数也没有调好。一直没有管去了,坐等结营小姐姐补充这部分的知识。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#定义DNN网络
class MyDNN(fluid.dygraph.Layer):
def __init__(self):
super(MyDNN,self).__init__()
self.hidden1 = Linear(100,100,act='relu')
self.hidden2 = Linear(100,100,act='relu')
self.hidden3 = Linear(100,100,act='relu')
self.hidden4 = Linear(3*100*100,10,act='softmax')
def forward(self,input):
#print(input,shape)
x =self.hidden1(input)
#print(x.shape)
x =self.hidden2(x)
#print(x.shape)
x =self.hidden3(x)
x=fluid.layers.reshape(x,shape=[-1,3*100*100])
y=self.hidden4(x)
#print(y.shape)
return y
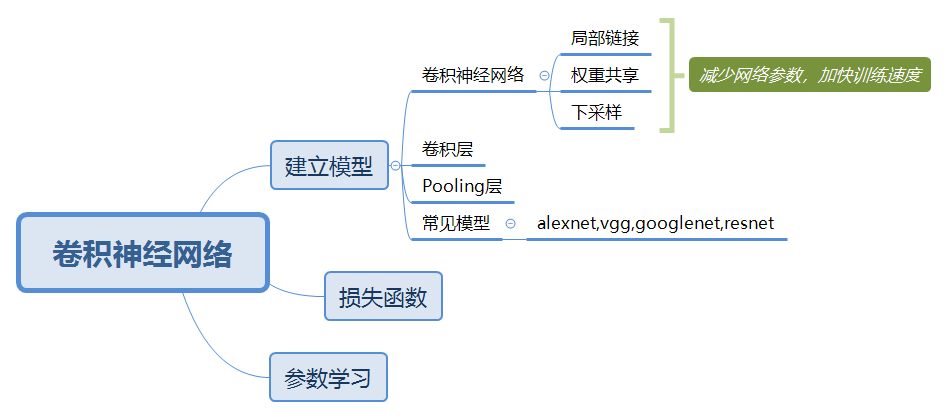
卷积神经网络原理与使用
使用步骤:
具体理解,可以参考一文让你理解什么是卷积神经网络
实战车牌识别
官方给的baseline太好了,完全不知道如何去修改,每次看到代码感觉都是一种享受~
分割字符的代码
存档,保存学习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 对车牌图片进行处理,分割出车牌中的每一个字符并保存
license_plate = cv2.imread('./车牌.png')
gray_plate = cv2.cvtColor(license_plate, cv2.COLOR_RGB2GRAY)
ret, binary_plate = cv2.threshold(gray_plate, 175, 255, cv2.THRESH_BINARY)
result = []
for col in range(binary_plate.shape[1]):
result.append(0)
for row in range(binary_plate.shape[0]):
result[col] = result[col] + binary_plate[row][col]/255
character_dict = {}
num = 0
i = 0
while i < len(result):
if result[i] == 0:
i += 1
else:
index = i + 1
while result[index] != 0:
index += 1
character_dict[num] = [i, index-1]
num += 1
i = index
for i in range(8):
if i==2:
continue
padding = (170 - (character_dict[i][1] - character_dict[i][0])) / 2
ndarray = np.pad(binary_plate[:,character_dict[i][0]:character_dict[i][1]], ((0,0), (int(padding), int(padding))), 'constant', constant_values=(0,0))
ndarray = cv2.resize(ndarray, (20,20))
cv2.imwrite('./' + str(i) + '.png', ndarray)
def load_image(path):
img = paddle.dataset.image.load_image(file=path, is_color=False)
img = img.astype('float32')
img = img[np.newaxis, ] / 255.0
return img
定义MyLeNet网络
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#定义网络
class MyLeNet(fluid.dygraph.Layer):
def __init__(self):
super(MyLeNet,self).__init__()
self.hidden1_1 = Conv2D(1,28,5,1)
self.hidden1_2 = Pool2D(pool_size=2,pool_type='max',pool_stride=1)
self.hidden2_1 = Conv2D(28,32,3,1)
self.hidden2_2 = Pool2D(pool_size=2,pool_type='max',pool_stride=1)
self.hidden3 = Conv2D(32,32,3,1)
self.hidden4 = Linear(32*10*10,65,act='softmax')
def forward(self,input):
x =self.hidden1_1(input)
#print(x.shape)
x =self.hidden1_2(x)
#print(x.shape)
x =self.hidden2_1(x)
#print(x.shape)
x =self.hidden2_2(x)
#print(x.shape)
x =self.hidden3(x)
x=fluid.layers.reshape(x,shape=[-1,32*10*10])
y=self.hidden4(x)
#print(y.shape)
return y
经典卷积网络解读
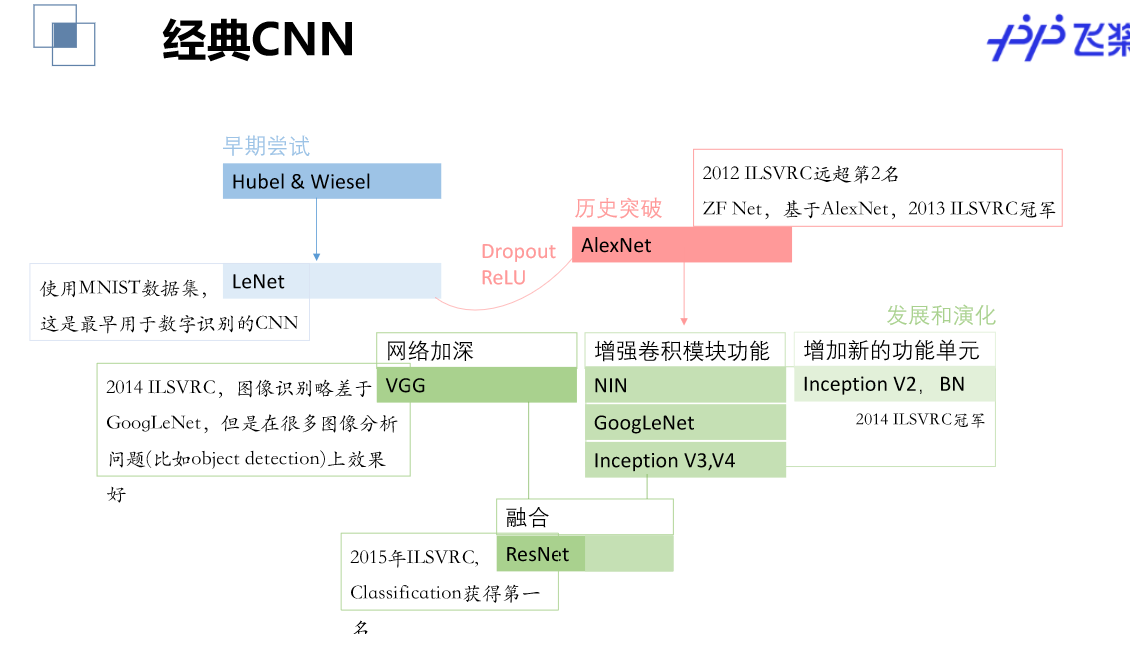
数据增强
常用的数据增强方式有:
对颜色的数据增强色彩的饱和度、亮度、对比度加噪声(高斯噪声)水平翻转、垂直翻转随机旋转、随机裁剪。
参考GitHub
计算VGG的参数
vgg的结构和参数量

小姐姐手算过程
参数
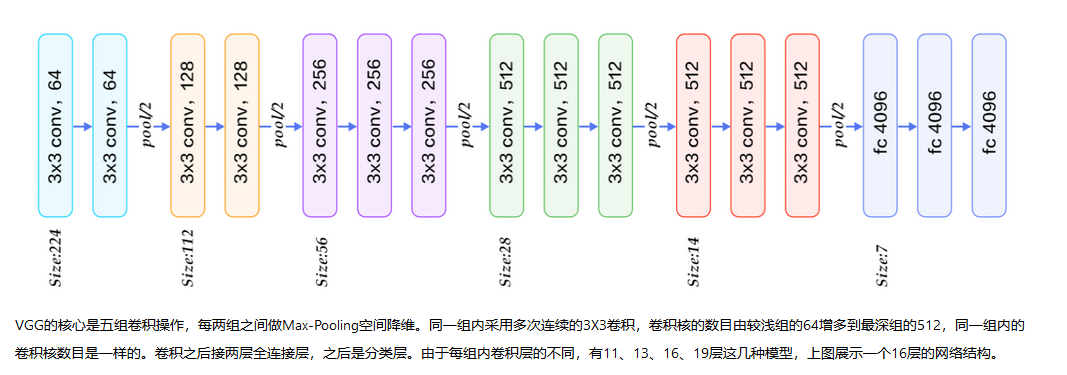 计算过程
计算过程

实战口罩识别
存档代码
官方给的baseline中优秀片段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
class ConvPool(fluid.dygraph.Layer):
'''卷积+池化'''
def __init__(self,
num_channels,
num_filters,
filter_size,
pool_size,
pool_stride,
groups,
pool_padding=0,
pool_type='max',
conv_stride=1,
conv_padding=1,
act=None):
super(ConvPool, self).__init__()
self._conv2d_list = []
for i in range(groups):
conv2d = self.add_sublayer( #返回一个由所有子层组成的列表。
'bb_%d' % i,
fluid.dygraph.Conv2D(
num_channels=num_channels, #通道数
num_filters=num_filters, #卷积核个数
filter_size=filter_size, #卷积核大小
stride=conv_stride, #步长
padding=conv_padding, #padding大小,默认为0
act=act)
)
self._conv2d_list.append(conv2d)
self._pool2d = fluid.dygraph.Pool2D(
pool_size=pool_size, #池化核大小
pool_type=pool_type, #池化类型,默认是最大池化
pool_stride=pool_stride, #池化步长
pool_padding=pool_padding #填充大小
)
def forward(self, inputs):
x = inputs
for conv in self._conv2d_list:
x = conv(x)
x = self._pool2d(x)
return x
myvgg
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
class VGGNet(fluid.dygraph.Layer):
'''
VGG网络
'''
def __init__(self):
super(VGGNet, self).__init__()
self.convpool01 =ConvPool(3,64,3,2,2,2,act='relu')
self.convpool02 =ConvPool(64,128,3,2,2,2,act='relu')
self.convpool03 =ConvPool(128,256,3,2,2,3,act='relu')
self.convpool04 =ConvPool(256,512,3,2,2,3,act='relu')
self.convpool05 =ConvPool(512,512,3,2,2,3,act='relu')
self.pool_5_shape = 512*7*7
self.fco1 =fluid.dygraph.Linear(self.pool_5_shape,4096,act='relu')
self.fco2 =fluid.dygraph.Linear(4096,4096,act='relu')
self.fco3 =fluid.dygraph.Linear(4096,2,act='softmax')
def forward(self, inputs, label=None):
#print(inputs.shape)
"""前向计算"""
out =self.convpool01(inputs)
#print(out.shape)
out = self.convpool02(out)
#print(out.shape)
out = self.convpool03(out)
#print(out.shape)
out = self.convpool04(out)
#print(out.shape)
out = self.convpool05(out)
#print(out.shape)
out = fluid.layers.reshape(out, shape=[-1,512*7*7])
out = self.fco1(out)
out = self.fco2(out)
out = self.fco3(out)
if label is not None:
acc =fluid.layers.accuracy(input=out,label=label)
return out,acc
else:
return out
人流密度识别的比赛
再次推荐大佬博客
大佬博客!!!! 真的,越读收获越大!!!
比赛的评分准则
注意事项
由于算的是距离的比值,所以一般情况下评测值都小于一,觉得超过1的很有可能是正反搞反了(加abs绝对值),要么就是预测大于两倍的实际了,而且次数还很多。
PaddleHub & PaddleSlim
这两个东西,我一片模糊,脑袋晕乎乎的,没有搞懂唉~
PaddleHub 介绍
PaddleHub 是基于 PaddlePaddle 开发的预训练模型管理工具,可以借助预训练模型更便捷地开展迁移学习工作,旨在让 PaddlePaddle 生态下的开发者更便捷体验到大规模预训练模型的价值。 github链接
PaddleSlim 介绍
PaddleSlim是百度飞桨(PaddlePaddle)联合视觉技术部发布的模型压缩工具库,除了支持传统的网络剪枝、参数量化和知识蒸馏等方法外,还支持最新的神经网络结构搜索和自动模型压缩技术。 GitHub链接
PaddleSlim实战
本次实践本来是要我们跑通一个demo的,但是没有看懂,加一直报错,遂放弃~~ 觉得baseline没有设计好,没有读懂,把api文档看了几遍,还是不懂操作。苦~
总结
本次七天实训收获还是非常大的拉,坐等证书邮回家。以前虽然听过,接触过很多深度学习的知识,但是一直没有操作,唉!白嫖真香。在群里也活跃(一般这种都是菜鸡~),和小伙伴们交流不同的想法,熬夜抢GPU,虽然用处不大,也很有趣拉。哈哈哈最后,不知道班主任的嫁妆究竟如何?
调惨的事宜
萌新一只,觉得经验甚少,坐等结营直播后在补充详细补充这部分知识 个人调参技巧一般都是暴力迭代,改变优化器,设置学习参数,学习参数大跑的快,精度不行。学习参数太小,跑的慢容易过拟合,可以加个dropout。


